3.0 Metacognitive proceduralization as modeled in ACT-R
The following section will explain the subject of metacognitive proceduralization in relation to the ACT-R code presented here. As explained in section 2.0, proceduralization is a cognitive process implicated in skill acquisition. A large part of proceduralization occurs when declarative knowledge is practiced and builds up task productions within procedural knowledge. As declarative knowledge is instantiated into productions, these 50 millisecond productions result in a speed up of task performance. This aspect of proceduralization can be expressed within the cognitive architecture ACT-R. Here, proceduralization within ACT-R will be explored as it is hypothesized to apply equally to both object-level knowledge and meta-level knowledge.
In ACT-R model #1, both knowledge and meta-knowledge are retrieved from declarative memory. As this process is rewarded there is a speed up in the time this process takes. In ACT-R model #2, declarative knowledge is represented in procedural memory as a dictionary list. The productions that are rewarded are subsequently preferred.
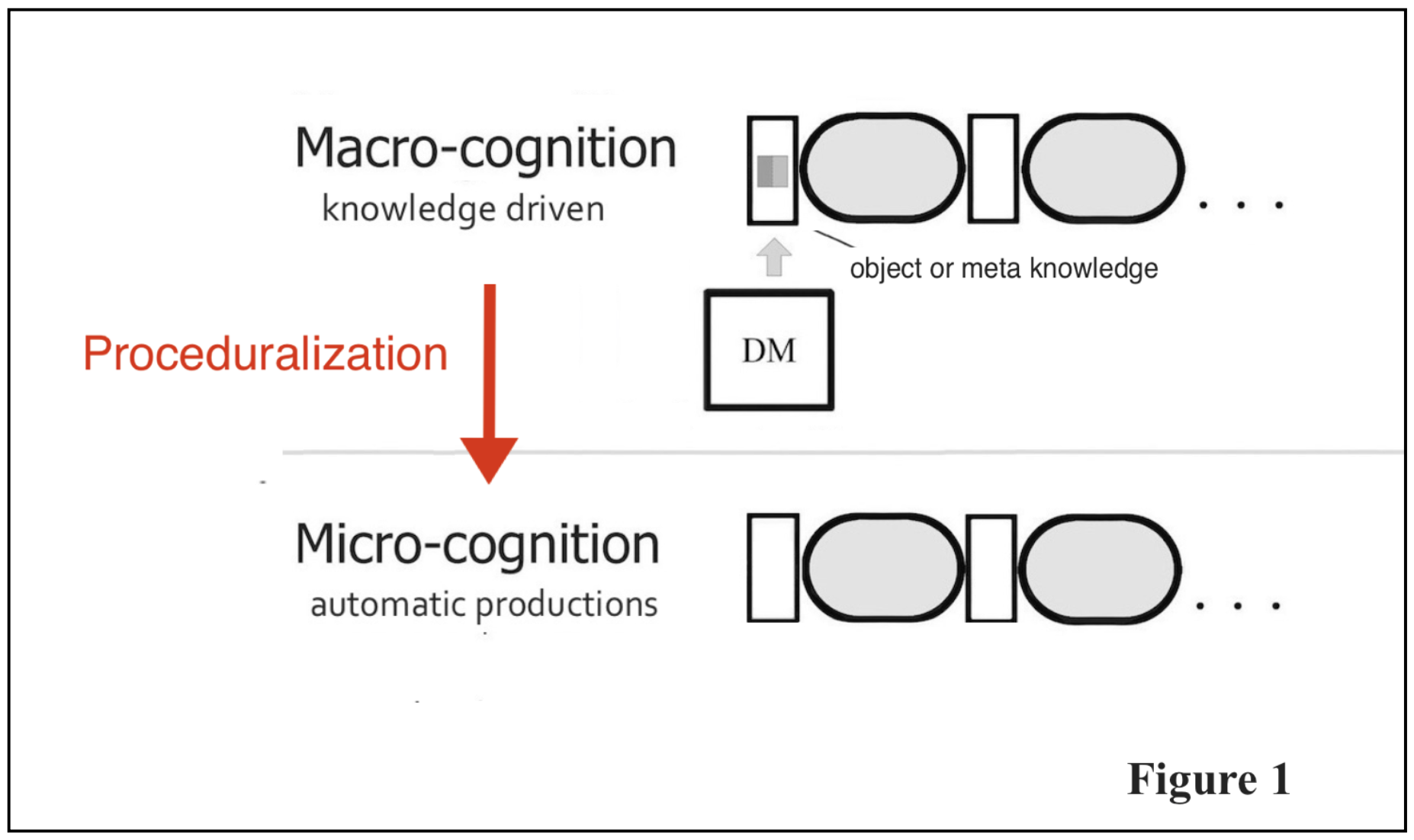
In ACT-R theory, proceduralization occurs partly due to a cognitive heuristic of “reward what is faster.” This reward operation cues a process of compilations that creates single or shorter chains of productions to replace longer chains. As shown here, regardless of whether the productions act toward goals that are object-level or meta-level, the productions move from being slow and knowledge-driven (macro-cognition) to being fast and automatic (micro-cognition). This aspect of proceduralization is depicted in Figure 1.
ACT-R code
https://github.com/BrendanCS/directed_studies_2020w/tree/master
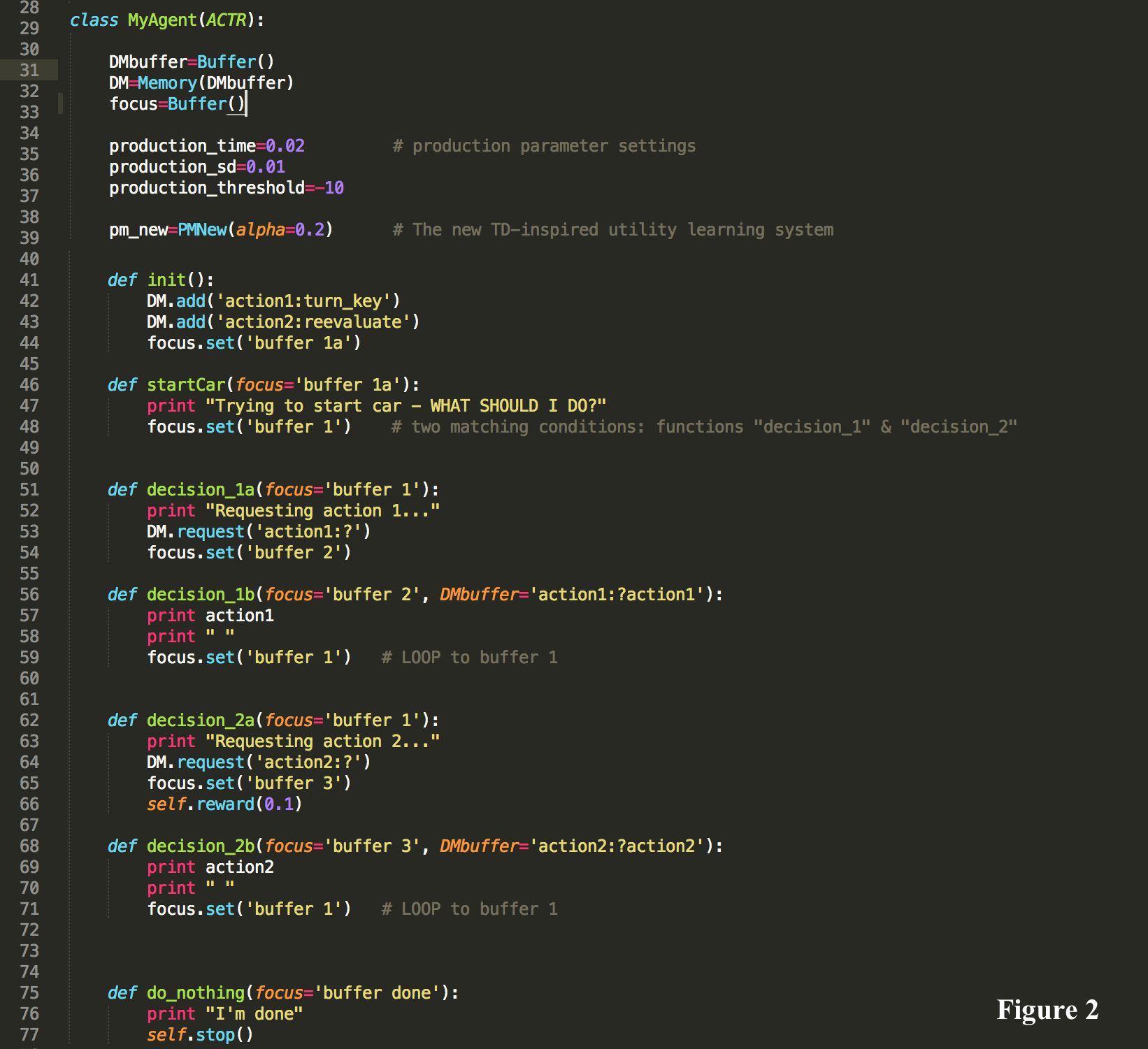
Model #1
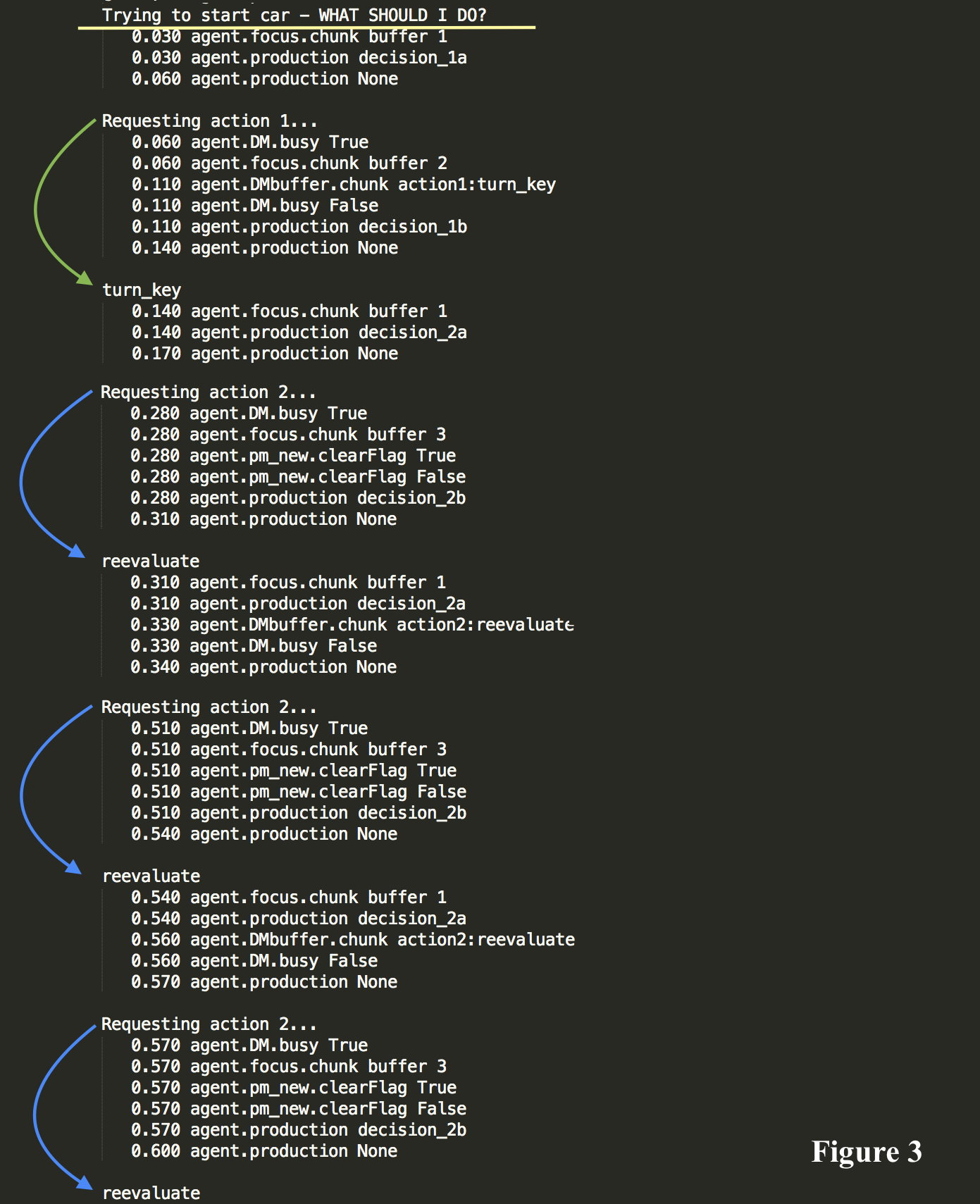
In this model employ utility learning. Here, both object knowledge (‘turn_key’) and meta-knowledge (‘reevaluate’) are retrieved from declarative memory. These two DM retrievals match the same initial condition in Figure 2. We see that ‘buffer 1’ matches both ‘turn_key’ and ‘reevaluate.’ Initially there is no preference or timing speed up as the unrewarded object-level DM retrieve is selected. As the code loops back to the beginning, and the meta-level DM retrieve is selected. This meta-level DM retrieve is rewarded and subsequently preferred in the following loops. This rewarded retrieval production produces a timing speed up (Figure 3). This utility learning helps to depict the process by which metacognitive process are learned by being rewarded when employed.
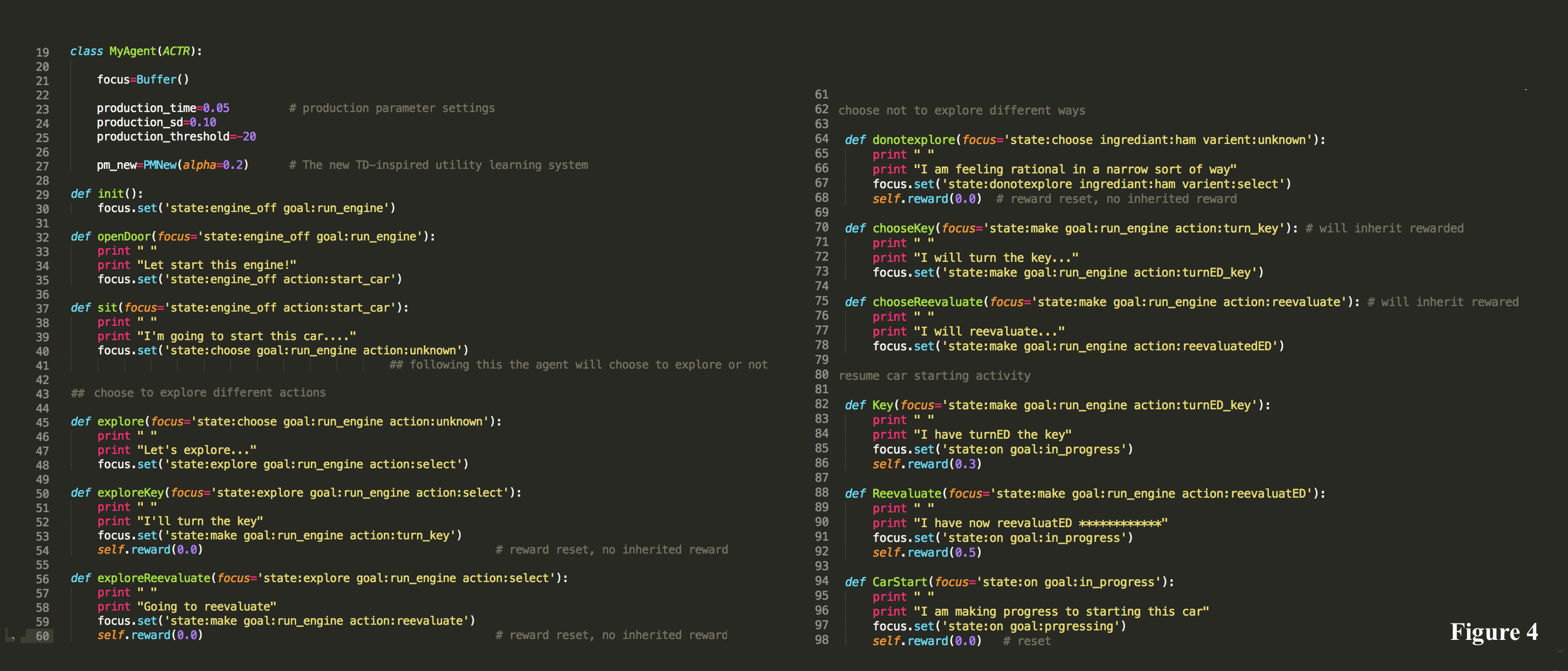
Model #2
In this model, declarative knowledge is expressed as a list, and so does not necessitate a DM retrieval. The meta-knowledge production (‘reevaluate’) is rewarded and is subsequently preferred along with a timing speed up (Figure 4).