Student as Partners Program

Big thank you to Ruth, for her invaluable support in my course this term. Her dedication and insight made a real difference for both the students and myself!
Metacognition in Human-Computer Interaction
Our lab’s latest paper, Metacognition in HCI: Designing Systems for Planning and Flexibility (Conway-Smith & West, 2025), explores how human-computer interfaces can be improved by modeling metacognitive processes like task switching, monitoring, and strategic adjustment. This paper offers a framework for designing adaptive systems that better support expert decision-making in dynamic environments.

In Memoriam: Steve Highstead

We are deeply saddened that Steve, a brilliant Ph.D. student in our lab, unexpectedly passed away on March 10th.
Steve was not only a brilliant scholar — with deep interests in ethics, cognitive modeling, and philosophy — he was also a kind person who cared deeply about ideas. He was well liked by everyone in the lab, and his presence brought warmth, curiosity, and thoughtfulness to every conversation.
He will be deeply missed.
Our thoughts are with his family, friends, and all who had the privilege of knowing him.
Brendan speaks at Stanford on metacognition in AI
AAAI 2024


New publication:
Toward Autonomy: Metacognitive Learning for Enhanced AI Performance. PDF
AAAI 2023 publication
See our new publication at this years fall symposium of the Association for the Advancement of Artificial intelligence
West, R., Eckler, S., Conway-Smith, B., Turcas, N., Kelly, M. (2023). Bridging generative networks with the common model of cognition. In AAAI Fall Symposium. Link
ICCM 2023

Brendan presents his paper at ICCM 2023 in Amsterdam: Metacognitive threshold (click on thumbnail to watch!).
ICCM 2023

Nico talks with Christian Lebiere after his presentation at the 30th ACT-R workshop in Amsterdam. Later that day day he presents his new paper published in the proceedings.
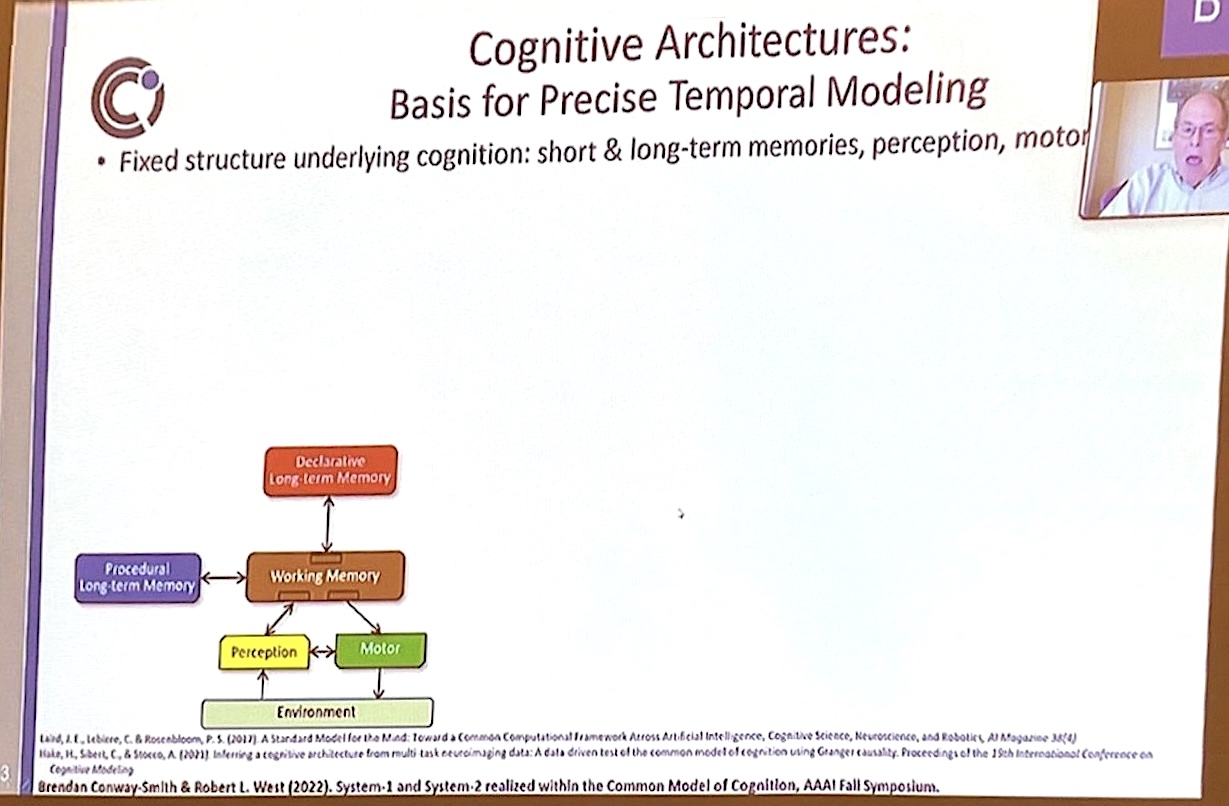
Fascinating talk by John Laird at AAAI – an honor to be cited in his presentation!